Tracking the flow of funding and other support to social sector organisations in Australia has historically been difficult because of inconsistencies in categorisation, or the absence of categorisation entirely.
Our Community developed CLASSIE to serve as a universal classification system for Australian social sector initiatives and entities.
Alongside CLASSIE, we developed an algorithm, CLASSIEfier, to mitigate the need for manual (human) classification. CLASSIEfier can classify historical records on behalf of grantmakers and other social sector supporters, and reduce human intervention in the classification of current and future records.
In 2016, Our Community launched a classification system for social sector initiatives and entities called CLASSIE. This taxonomy, based on the US-based Philanthropy Classification System, provides a tool for classifying information related to Australia’s social sector in a standardised way.
Up to $125 billion is disbursed every year in Australia, but we are yet to establish a clear overall picture of the flow of grants funding by sector, location and beneficiary. CLASSIE enabled us to start filling in the blanks.
Once CLASSIE was developed, some of its sections were incorporated into Our Community’s grants administration platform, SmartyGrants, enabling grantseekers to select the subjects and populations of their grant applications, or the grantmakers to do that on their behalf.
However, manual classification – using humans to read and classify each application – is time consuming. Moreover, current and future applications represent only a fraction of the data we would like to classify, given that SmartyGrants holds more than 400,000 historical grant application records.
Against this background, CLASSIEfier was born. CLASSIEfier is an algorithm designed to automatically classify grant applications, or indeed any relevant social sector data. Initially, CLASSIEfier classified against the CLASSIE taxonomy, but later versions of the algorithm now offer other dictionaries to classify against in addition to CLASSIE.
CLASSIEfier 2.4 launched in 2020 and CLASSIEfier 3.0 launched in 2022, embedding the United Nations Sustainable Development Goals (SDGs). Grantmakers can now use CLASSIEfier to track the progress of their own goals towards the SDGs.
In 2025, CLASSIEfier became widely available to SmartyGrants users, enabling grantmakers to instantly classify their past and current grants.
How does CLASSIEfier work?
CLASSIEfier is an algorithm that reads a grant application – or any text related to the social sector – and predicts the main subjects, populations and SDGs involved.
Initially, we considered using a machine learning algorithm to build CLASSIEfier. However, such algorithms must be trained with a large set of pre-labelled applications to learn the representative writing patterns and vocabulary of each CLASSIE category – something that we didn't have when building the algorithm.
Our testing showed that at least 2000 applications per CLASSIE category were needed to generate good results. Each CLASSIE subject has 900+ categories, which meant that more than 180,000 labelled applications were needed. It was impractical to reach those kinds of targets by manually classifying the data.
After extensive trials and research, we discovered that we could successfully extract keywords from the SmartyGrants database and create a controlled vocabulary to describe each CLASSIE category. We landed on creating an algorithm that follows a keyword-matching model to perform auto-classification.
A keyword-matching model
Keyword-matching is a common technique used to find keywords in text. We use keyword-matching relying on the hypothesis that certain combination of keywords can be used to describe a CLASSIE category.
The model uses three different groups of keywords and applies certain rules for each category:
- Unique keywords: They would be a clear and distinct representation of a CLASSIE category.
- Context keywords: They can be general keywords but will complement the unique keywords and give meaning to the text.
- Exclusion keyword: When these keywords are found in the text a category can be excluded even if there was a match of unique and context keywords.
See the example below. With the keyword-matching algorithm we can classify social sector text with 80% accuracy.
 This is how the keyword-matching model works for the CLASSIE category "Cancers".
This is how the keyword-matching model works for the CLASSIE category "Cancers".
While developing CLASSIEfier, we concluded that it was not currently feasible to classify human natural languages with 100% accuracy. We found many cases where keyword matches led to a wrong classification. For example, an application containing the words "church", "religious" and "Christian" would be classified under "Religion" even if the application concerned a fete at a Catholic school.
We are exploring this issue by constantly searching for biases and involving third parties in CLASSIEfier's testing. You can read about our examination of biases in CLASSIEfier and our attempts to address them in Ethical considerations in multilabel text classification.
The hierarchy of classifications
CLASSIE comprises a hierarchical taxonomy, where many categories themselves have “child” categories.
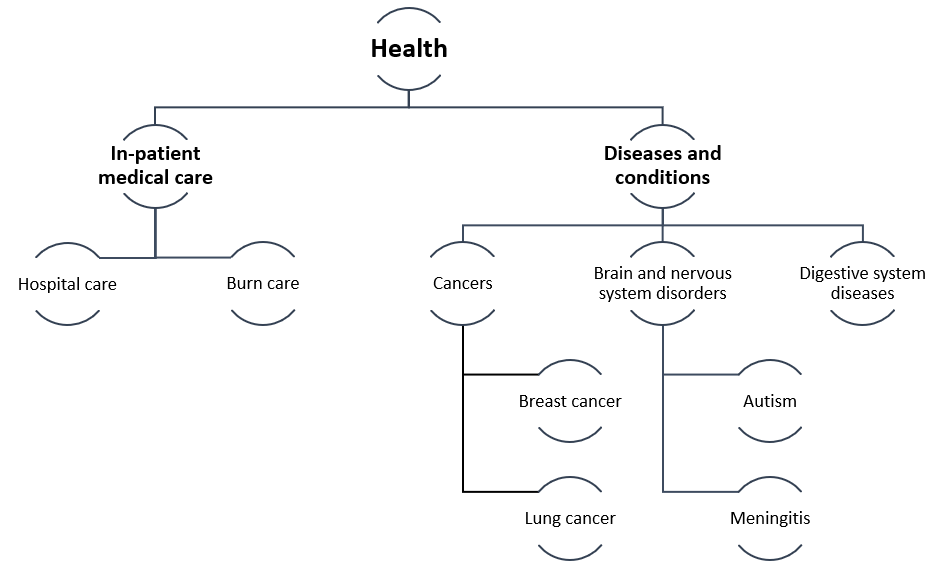 This is a simplified view of how CLASSIE subjects are structured, with the actual taxonomy including many more categories.
This is a simplified view of how CLASSIE subjects are structured, with the actual taxonomy including many more categories.
Consider a grant application aimed at helping teenagers with autism. This application will have the following classifications:
Subjects:
- “Health” at level 1
- “Diseases and conditions” at level 2
- “Brain and nervous system disorders” at level 3
- “Autism” at level 4
In classifying this application, the grantmaker or grantseeker may select the level 4 category “Autism”; doing so will automatically nest the application in the corresponding classification at higher levels (“Brain and nervous system disorders”; “Diseases and conditions”; “Health”).
Beneficiaries:
This application will have two beneficiaries:
- “Children and youth (age 0-17)” at level 1
- “Adolescents (people aged 13-17)” at level 2
And also, perhaps:
- “People with disabilities” at level 1
- “People with intellectual disabilities” at level 2
As this example shows, most grant applications can be categorised by more than one label, which of course increases the complexity of CLASSIEfier.
To overcome this challenge, the algorithm runs from the higher levels to the lowest levels. It first matches the keywords in the most detailed categories (level 4 in Subjects and level 3 in Populations) and rolls the classification back to less detail if needed.
Additional taxonomies have been incorporated into the algorithm by mapping and re-using CLASSIE keywords. For example, in adding the SDGs to CLASSIEfier we first mapped the goals to CLASSIE categories. The SDG 3 "Good health and wellbeing" aligns with CLASSIE "Health" categories at all levels and "Sports and recreation" categories at some levels, particularly those related to fitness and wellbeing.
For more details on the SDG-CLASSIE correspondence see The Future of Funding: How well are Australian grants addressing the UN Sustainable Development Goals?
One CLASSIEfier, multiple uses
CLASSIEfier classifies almost any text relating to the social sector. We offer this tool for use to grantmakers and other social sector supporters who wish to understand more about their own funding and support patterns, and by those who wish to know about and participate in mapping of universal trends.
As a initial step, we released a report that used CLASSIEfier to analyse funding flows within SmartyGrants: The Future of Funding: What are the priorities and directions of Australian grantmakers?
Beyond the SmartyGrants system, the tool can be used to classify data in GiveNow (our donations platform) and Funding Centre (our grantseeking database). External uses may be found for the tool too. Thus we can begin to illuminate trends and make comparisons within accounts or domains as well as within and across sectors.
CLASSIEfier is the first of many artificial intelligence initiatives that Our Community is pursuing.
MORE: About the CLASSIE system | Our Community Innovation Lab